
09/25 It’s only been a month and this is very outdated already.
Qwen models are some of the best models I’ve used, period. I’ve been using them for a few years and generally when I see an option to use a Qwen model, I’ll pick that.
Qwen has been mostly image to text (which they’ve excelled at along with InternVL which I believe is a fine tune of Qwen). Qwen-Image is their first T2I model (at least that I’m aware of).
I generally quickly test each diffusion model when it comes out because I have a need for much better prompt following and quality for other projects I’m working on (the itch not scratched so far).Flux1d, Hidream, Cosmos, SD3, all pretty good. Noting that Stable Diffusion 1.4 came out in August of 2022, 3 years ago, I think we’ve come a long way. Qwen uses one TE (as opposed to at least 2 for most other models and 4 for HiDream (!?!). Turns out you only need one really good one.

Naturally Qwen uses their own Clip TE which is 2.5VL 7B (already using this one for TE in ComfyUI, a fantastic model). The VAE is also theirs. I’m not surprised that their text representation is above par because the makers of Qwen are incredibly good at training I2T models.
Let’s try something hard.

Ok well progress to be made either way…Not using BF16 so perhaps that’d help a bit (probably not enough)
Ok, let’s try again. Lets use a stronger Qwen model to generate the prompt to feed it back to itself (QW3-A30b-3b) (thinking model) of which the 2.5VL 7B CLIP will handle it. The input text to the model was “expand upon creatively for a diffusion model prompt: “A vibrant scene: cats walking down an old street in Amsterdam with traditional Dutch pavers, each wearing miniature wooden clogs. Text at the bottom reads “Cats in Clogs”, Qwen 3’s result below:

Key Enhancements:
Dynamic lighting: Golden-hour glow adds warmth and depth.
Historic authenticity: Cobblestones, canal boats, and tulips anchor the scene in Amsterdam’s culture.
Cats’ clogs: Detailed, colorful klompen with cultural context.
Text clarity: Bold white font with black outline ensures readability against complex backgrounds.
Whimsical elements: Catnip ‘C’ and playful cat interactions elevate creativity without overwhelming the composition.”
Pretty good.
08.11
Did one additional test this morning- This was to test both the encoder and the model. I used a distilled LoRa because even with a few 4090’s the inference time for 20-30 steps was minutes. Kijai made a “lightning” LoRA in a matter of hours it seems that dropped the steps to 8-10 and with impressive results and after some model strength tuning got the output practically identical to the base model output w/o a distilled LoRA. . As I asked on HF, does this guy sleep? Anyway, 8 steps being doable for testing for a few hours and not time for a few days, we ran it:
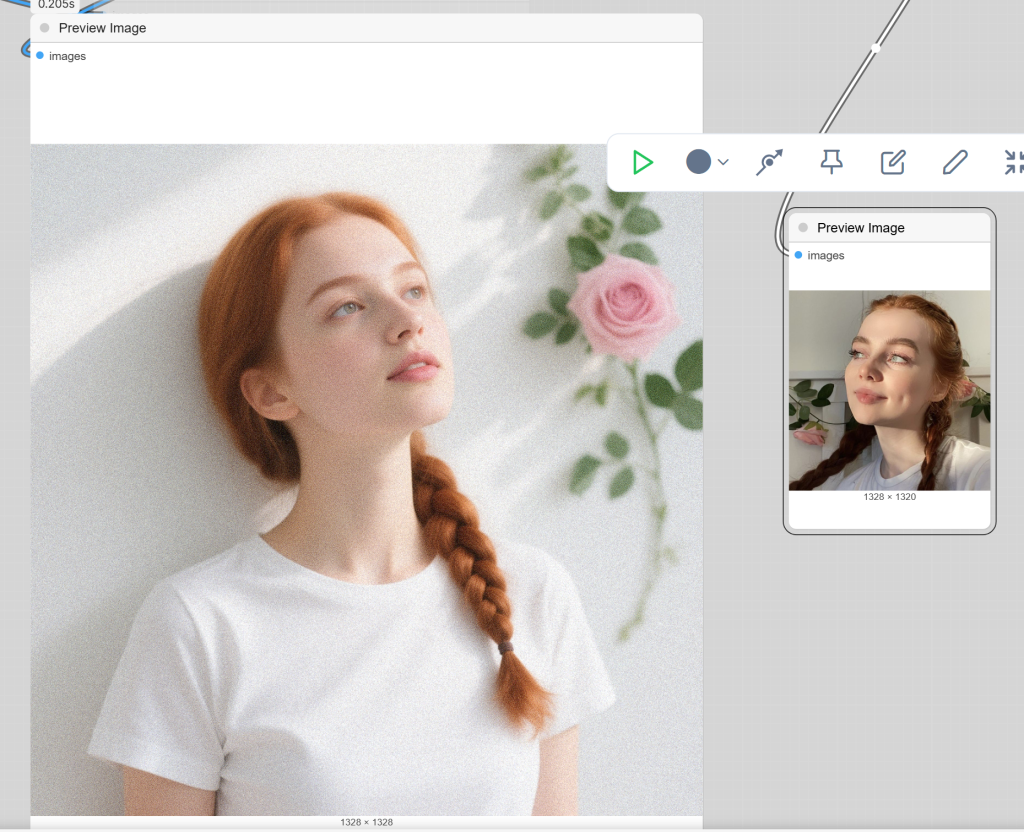
Pretty good for their first effort. Kijai too.
08.21
The Qwen-Edit model was released a few days ago. Long-term these sorts of models may dramatically reduce the need for custom LoRA’s.