

(WIP May 2025)– Caveat Emptor: I am not a graphic designer. Obviously.
I’ve been using ComfyUI for a few years (way back when it had only a few *thousand* stars). I think it may stand out (soon/already?) as a tool that turns into something people will pay people to use professionally (like Photoshop, Indesign, etc). I was immediately hooked on how the workflows are visual and there are so many options and (so many) ways to do things. As a visual person and a photographer of over 25 years, this is my jam.
ComfyUI is a framework (ish) where people build nodes on top of to achieve practically any task. Many tools that were CLI based have been written as ComfyUI nodes (or front-ends, really). Examples include FFMpeg, ImageMagick, and Ollama to make the point about them being connectors to tools that already exist . At some point soon I can imagine almost every single useful tool have a ComfyUI node as a matter of course. That said, Comfy ships with enough core nodes to get a lot done so it’s not exactly just a framework.
ComfyUI has a visual framework that is built on creating flows (“workflows”). Generally the flow starts on the left and moves to the right. Although it doesn’t have to. It is indeed an excellent tool for diffusion type processes, but has expanded (quickly) to provide access to all sorts of non-visual tools.
Here’s a shockingly simple way to do something in CUI- Let’s remove a background.
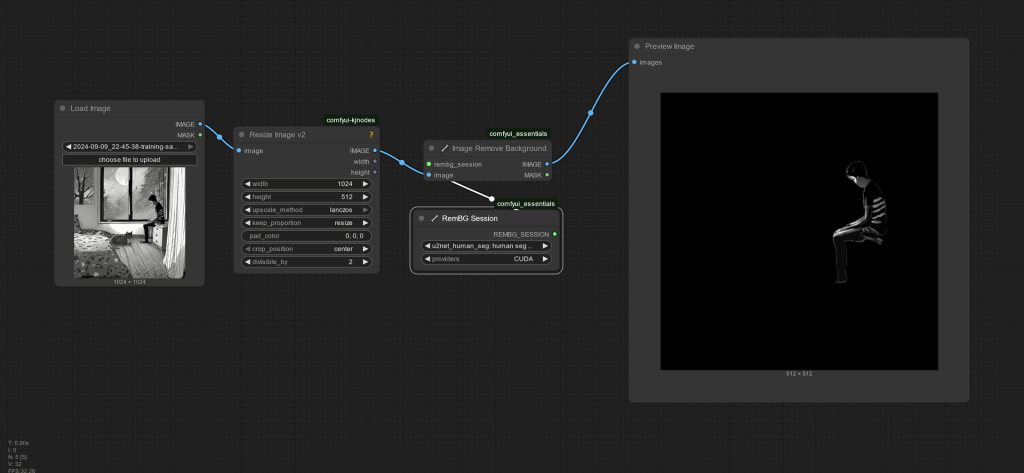
I never understood why working harder to do something simpler had it’s critics. I suppose if you just enjoy the process and not the output I could see that. If you’re just trying to troubleshoot things and be analytical, I can see that too. But for this example I need to separate this boy from the background. And I need to do it with another 5500 images. So the process looks something like:
- Load image (built-in)
- Resize image keeping scale (an external node) (resizing is key for crucial for speed among fitting within training guidelines of a diffusion model) e.g. SDXL wants 1344x at highest res.
- Pipe image to rembg node (built-in)
- Choose what type of model to use for background removal (I chose humanseg because I wanted to get rid of the cats), chose CUDA because, faster. (Although CPU is very fast as well for something this simple) (built-in-node)
- Output
- Iterate
Naturally you could crop this image, or pipe straight to a cropped image, and whatever else you can imagine. You could turn the output into an alpha channel, for example which is good for training characters. You could turn this into a batch to iterate through x images through various nodes. It’s a very very handy UI for automation. In fact for video/imagery and maybe even LLM’s I’d say it’s the best tool out there.
Load, resize, describe, and generate another image.
Another more complex (but still simple) workflow. This uses Ollama as the backend and a Ollama node for the frontend. So, in Ubuntu or WSL2 we’re almost done after snap install ollama. After that all we need is a decent Vision model which there are many (Qwen2.5VL++). Lately, I’m using Gemma3-27B at home but in a pinch let’s use the 3B variant which is a fairly small 3.3GB – Could be a whole other post but the quality of Vision models has grown exponentially (!!) from Llava 1.5 to LL3.2, G3 and QW2.5VL in a year. Does anyone even remember Moondream2 anymore (just kidding, it’s great for edge cases) and at ~1.5GB for float8 I mean..wow. To not even to have to bother with quantizing..
Here’s a simple workflow to have an LLM re-describe and image as an “expert” and output it’s opinion:
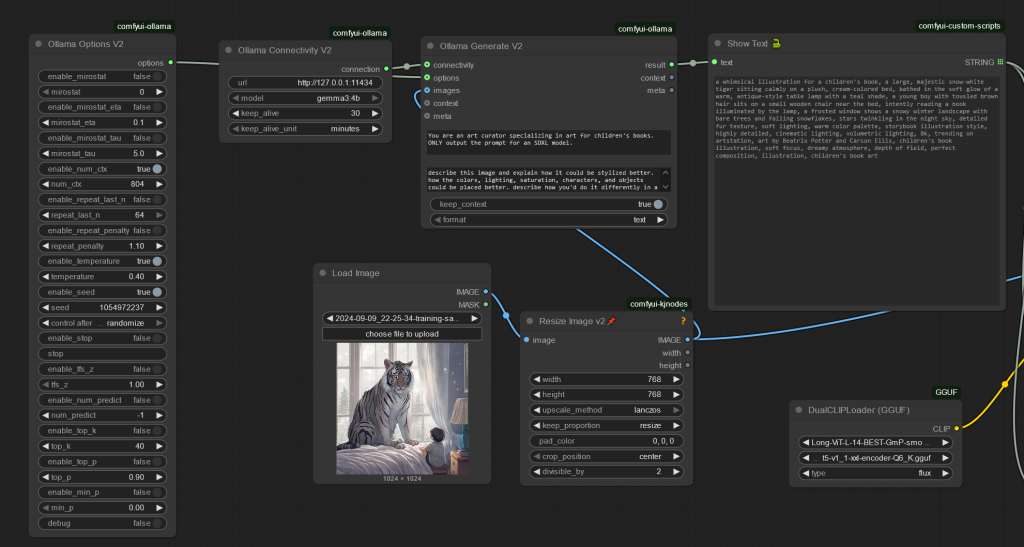
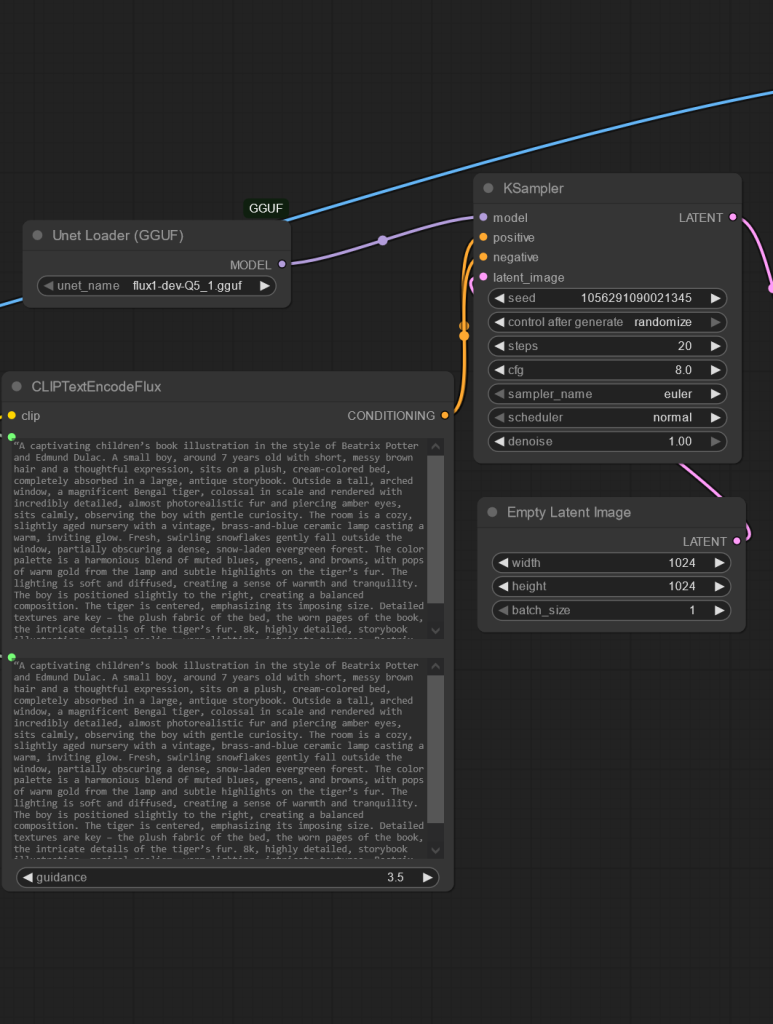
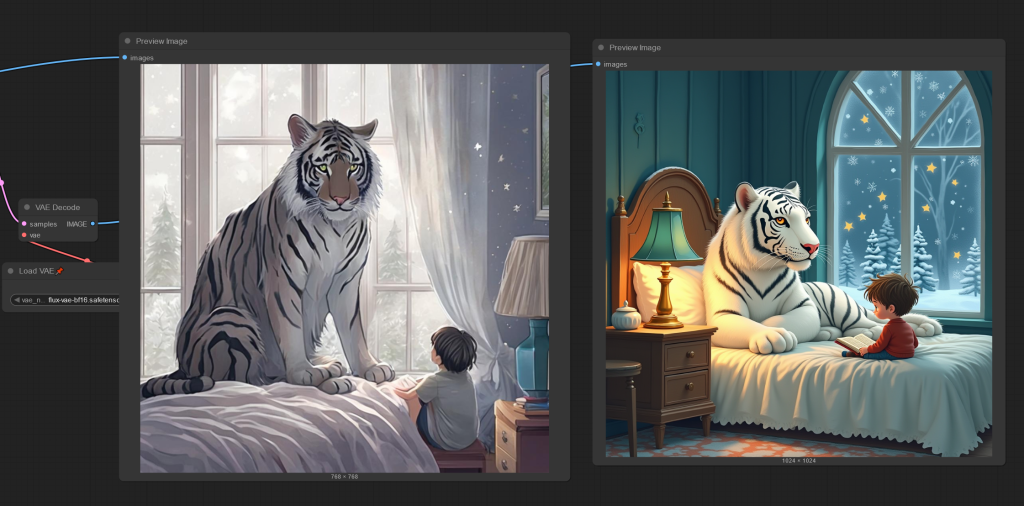
So, tiny little workflows like this are 5 minute operations from building to running. That’s pretty good considering the process. Naturally I could iterate through images or even basically create a For loop that would further enhance the image as needed. Or upscale, or whatever.
An aside…
I have a tendency to use the smallest models I can find for the job (doesn’t matter if it’s an LLM or a diffusion mode). When I had unlimited gig internet I’d generally download float16 and 32 models which is still slow to download and even more annoying to wait for it to fill up your VRAM. things improved when GGML came out and TheBloke went crazy quantizing everything (thank you sir for your service, where did you go anyway?). (llama.cpp is essentially the primary tool to dramatically reduce the barrier to entry to these large models). Speaking of, they’ve added 60K stars in the last year too. Anyway, I digress.
Go check out CUI and have fun with it. It’s built a big user base and it’s only going to get bigger. Make sure to install Comfy Manager as your first order of business. FYI I use WSL2 exclusively and it works fine and dandy like cotton candy.