
More GPU-centric these days so changed up some stuff. This setup works pretty well. I’m always trying to serve more with less while avoiding cloud as much as possible. There are automated jobs handling replication to s3 endpoints for critical backups. I dedicated a host to inference with a 3090TI. As inference tools improve the 3090TI becomes more useful. I can fit a lightly stepped on Qwen 3.5VL 35b quant fully on the GPU that provides excellent inference (for my needs) which is part of other workflows, described below. That’s about 99% of what the GPU does inside WSL2. Why run inference in WSL2 and not in Windows? I think it outperforms Windows even sitting inside of a container. Second, it allows me the unix tools I already know to move stuff back and forth, API calls, etc. I tried using LMstudio on Windows once with their Open-AI like API service turned on and it was a slog. Maybe better now, it’s been a while.
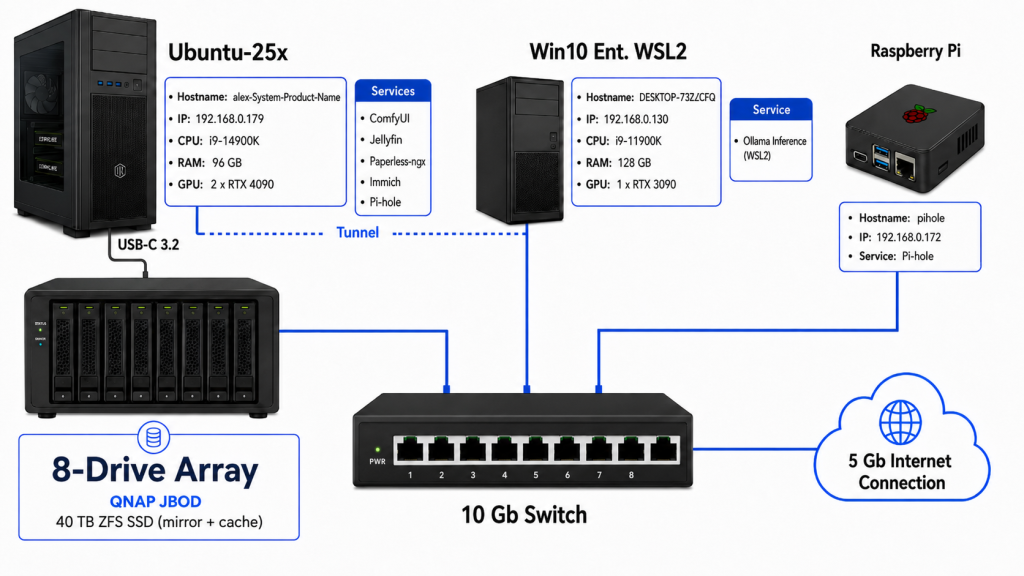
Every service on the U25x (my hand was forced for 25.10 for HDR- well, if I wanted to stay in my Wayland config) box except Pihole (secondary) use the GPU’s in one way or another. Obviously,
Jellyfin can use NVidia libs for hardware accel/transcoding. I use:
paperless-gpt which works with paperless-ngx to use an LLM (a lighter weight Qwen 9B VL mode on the WSL2 host running generic u24.04 server) to infer the I2T content instead of Tesseract (for probably obvious reasons). It also generates metadata well.
Immich has a rudimentary CLIP inference workflow that I turned on- it’s super lightweight so we run that on the same server. It uses NV libs for transcoding video so that’s good.
Pihole sits alone doing it’s thing as a secondary to the primary raspberry pi server. The 4090’s spend the most time doing ComfyUI stuff,
Lately for diffusion/reverse flow diffusion I use Flux.2 (fp8 best I can efficiently do) lately for building educational materials and short stories. I generally spin up some cloud GPU like Runpod when doing stuff like LoRA training etc. Mistral alone makes Flux.2 the obvious choice for me (for strictly image generation, at least). 6000WK for the cheap win on RP. A lot of competing models came out between Flux.1 and Flux.2 and I tried a bunch of them (some with 4 LLM’s) and Flux.2 still is superior IMHO. Qwen-Image is pretty good too.
Some other things going on not in this diagram are workflows to copy photographs and videos on my devices to local storage. Watch folder takes in, sorts, adds a paragraph description via a edge LLM (currently Qwen 2.5VL 3B). to IPTC metadata in images (for now) and usually succeeds in tagging people it’s seen before in the metadata. I’ve always liked using EXIF and IPTC. From my purview it isn’t leaned on enough. AI tells me abliterated (refusal trained) models suffer but I’ve never seen that.
Why? Purpose? None but == fun. That’s a purpose.
Things in my little home infra are in fact so GPU heavy that except for occasional scheduled jobs the CPU’s are essentially idle. The “server room” is also a good room to germinate seeds without a heat mat.
I9’s tear through ffmpeg workflows w/o any sort of NVENC (parallels) so I have various jobs that run around and look for new media to transcode (for example, for Jellyfin > Roku > Jellyfin App). I also have a cheap projector that only reliably does h264/AAC. None of this stuff is a rush so perfect CPU work. It’s all pretty efficient.
I haven’t had any need to mess with AI Agents which are as popular as the invention of the popcorn popper as of this writing. I’m sort of glad I’m waiting for things to shake out a little longer because it seems that a lot of these programs like Openclaw + vibe coders == 0wn3d. Ok i’m into agents now.
P.S. It’s annoying you need to actually get signal from a device to see resolutions via X (remote connecting via NoMachine) . I will say canceling Amazon made it annoying to buy a DP or HDMI dummy adapter.
TBC.