
The infra engineer that was supposed to die in 2010
(alternative title- Agents are expensive in all ways.)
Around 2010 I kept hearing that DevOps was going to kill the infrastructure engineer. A developer spins up an instance, clicks deploy, done — who needs the infra person? It never happened. What mostly happened was exhausted developers who didn’t want to care about infrastructure, and a lot of security problems in the deployments. I can’t recall a single person who lost their infra job because a developer could now do it themselves.
Fast forward to today and the same energy is everywhere. Different technology, same fear, same posts, same FOMO. The pattern’s clear if you’ve been around long enough to watch a few of these cycles.
The cost nobody’s budgeting for
Everyone’s standing up agentic workflows as fast as they can, because the pressure to show AI adoption is again, the fear of missing out. What’s less visible is what it costs to run these things at scale. Token burn, failed runs, re-prompting, orchestration overhead — that adds up fast. You know what else adds up? Sinking money into companies to monitor those metrics.
Prepare to spend. A lot.
Agents need babysitters
Some AI nerd should make a t-shirt that that reads “Context Drift”, it would sell dozens. Agents forget their own rules, hallucinate state, act on stale or misinformed context, and drift from what you told them to do the longer they run. So you end up writing cron jobs and audit routines to double-check the AI — verification loops to make sure it didn’t do something it wasn’t supposed to. Basically a small engineering project just to keep the agent honest, on top of the agent itself. Overhead.
Right model, right job
I don’t run large scale AI in production (I don’t run AI in production at all except for my own needs). My guess though is this is where a lot of hidden waste lives. Defaulting to the most capable model for every task in a pipeline, because it’s easy to configure, is a common pattern — and it compounds fast when agents are running multi-step workflows.
The practical question before calling any model: does this task actually require reasoning, or is it extraction, classification, or formatting? Is it simply doing sentiment analysis? You can run RoBERTa on a C-64. Routing a document through OCR post-processing, pulling structured fields from a known template, classifying a short text into one of five categories — none of those warrant a reasoning model. A lightweight local multimodal model running on consumer hardware, or a smaller API model, may do the job equally well.
Where the more capable models sometimes justify themselves: genuinely ambiguous long-context tasks, multi-step reasoning where intermediate errors compound, cases where quality degradation has real downstream cost (money or effort, dealer’s choice).
The problem isn’t that the big models are bad — it’s that agents tend to call them by default for work a smaller model handles fine. Anthropic and OpenAI aren’t going to be kicking down your door telling you to use a cheaper model, incidentally.
Small multimodal example…
Anthropic’s Haiku is a really REALLY good model in the scheme of less expensive models and something like $1 for 1M tokens. That’s a lot of tokens to do basic stuff. PERFECT for OCR for example. Make sure you resize those images though (1092×1092 is the ideal so scale long as needed). Someone may say, “it’s only $1 for a million tokens!” but one million tokens adds up fast with an image pipeline. Really, really fast. At ~1092×1092 (or roughly just over 1MP) that’s 1568 tokens per image post-processed! That’s 637 images. Aka nothing. FWIW- They don’t publish MMMU for closed models but I bet if you did the Pepsi challenge again a Qwen 3.5 MOE it would either match or exceed Haiku’s performance for vision tasks.
I don’t think people with big token budgets do this but.. Qualifying the model before the call means asking what the task actually needs: deep reasoning, or just accurate extraction? Well-structured input or ambiguous? Are we asking a seriously complicated engineering question across two dozen agents doing 100 tasks? What’s the acceptable error rate? I think that question should be asked early.
I think this part probably needs a human in the loop, at least for now. Models change constantly. A router (in the AI sense) calibrated six months ago may be pointing tasks at something since superseded. Someone (that being someone that can ingest ice cream) needs to evaluate it against the actual task types in the system and make a deliberate call about how it gets used. Not because agents can’t make decisions, but because the landscape moves fast enough that automated assumptions about model quality go stale. If you think AI is going to completely replace humans for anything harder than running superpowered crons, I think you’re gonna have a bad time.

Lorenz stuff…
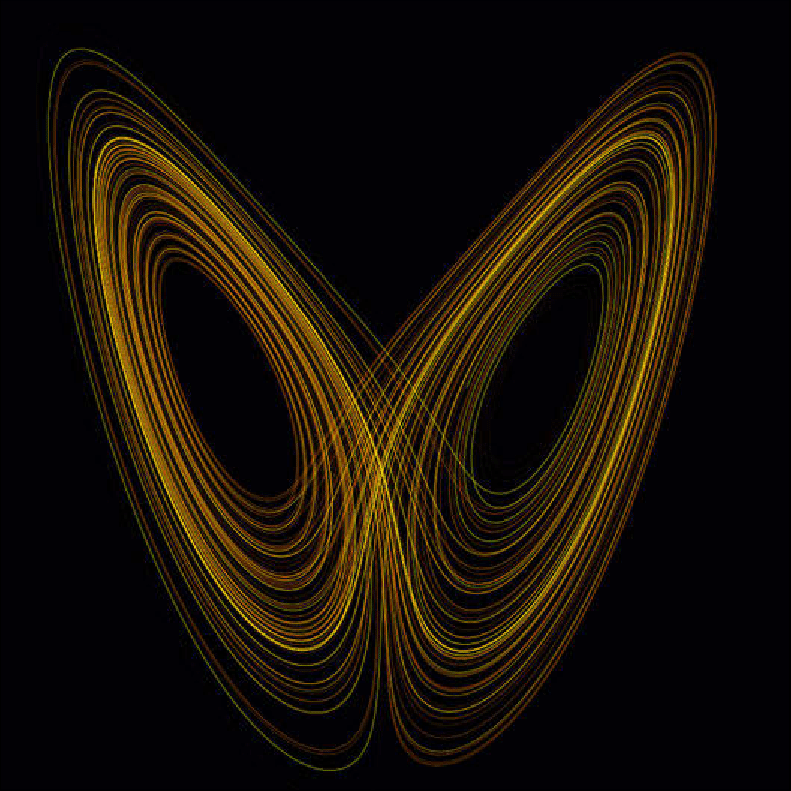
There’s something Lorenz-adjacent I’ve thought about often and in many contexts. In a chaotic system, a strange attractor doesn’t look dangerous from the outside — the system appears to orbit something stable. But sensitivity to initial conditions means two trajectories starting almost identically diverge exponentially. A slightly wrong model choice upstream — something trivially off, a classification that’s 90% right instead of 99% — can behave the same way inside a multi-step pipeline. The error doesn’t look like an error at first. It follows a plausible path. The output of a misrouted task becomes the input to the next, and the divergence compounds through each step until what surfaces downstream looks nothing like the original cause and is much harder to trace back.
Agentic pipelines aren’t chaotic systems in the mathematical sense. But the sensitivity to upstream perturbation is real, and the image — broken loops generating more loops, orbiting something that looks like correctness while drifting further from it — seems about right.
TLDR; garbage goes downhill and picks up more garbage on the way down…
Agents in production
Context limits get blown through faster than expected, and nobody remembered to summarize prior turns to keep the window manageable. The agent is now operating on compressed, lossy context and making decisions based on it. Maybe summarizing would lose a few keywords that would completely sideways something else downstream…
Ideas- just ideas..And they may already be happening..
Structure ground truth into config that reloads each session rather than relying on the agent to remember it. Use hooks that re-inject rules at the tool-call level. Push notifications through the API so the agent can reach you when something worked, when something broke, when it gave up — rather than running silent. That kind of real-time signal is what makes automation something you can trust rather than something you check on later and hope went fine. But, is this too much work for something that is supposed to be less work? Did we create something that requires more work to keep it honest? E.G. Is this really worth it? Yet?
Interactive work…
The live-session blind spot is harder. An agent in a long interactive session is turn-based — it can’t push anything to your term until you send a message. The only real controls are max-step limits and scope constraints baked into the prompt. For scheduled async runs, tying alerting to job completion gives you cost and outcome per run, which is at least tractable.
“LLM observability”- I heard this term recently. You mean monitoring something? Okay. So out of the gate we know we have to monitor whatever it is AI is doing. Not just to say “wow this sure is swell” but “wow this sure is expensive”. I’m not trying to be negative about it, but thinking more about actual scaling/bankruptcy. Cloud was supposed to be the panacea. You paid for only what you used. Remember all that? Not even to begin talking about vendor buy-in with LLM’s!
A token is a terrible thing to waste…
Microsoft rolled out an AI coding tool to thousands of engineers and canceled most of the licenses six months later — too expensive. Uber’s CTO said the company burned through its entire 2026 AI coding tools budget by April. Nvidia’s VP of Applied Deep Learning put it bluntly: for his team, the cost of compute runs far beyond the cost of the employees. Goldman Sachs is forecasting some insane amount of token consumption driven by agents — and notes cheaper tokens won’t fix it, because agents require far more tokens per task than standard models. I heard some company blew through 500M of spend in a month on runaway agents on Anthropic but not gonna believe that.
None of this means agents are a bad idea. It means the operational discipline hasn’t caught up with the deployment speed. Yet it gets deployed anyway. And more often than not you hear some shit about some company getting stung/owned/going bankrupt from all of it. This is almost exactly how “Cloud” started. People had no idea how to budget for it until they were millions in the red, then they started adjusting their usage. For the most part Cloud is still drinking 3/4 of your milkshake while you paid for all of it.
How do you quantify success?
“I deployed agents” and “I got measurable ROI from agents” are very different sentences.
The infra engineer didn’t die in 2010. The question with agents isn’t whether they’ll replace someone — it’s whether the bill makes sense before the novelty wears off, and whether you can actually see measurable output from essentially a black box. I’d say probably not (right now).
Now let’s talk about token burn w/r/t the environment…..All those (previously) hipster-programmer-forward .com’s are about to be worse than the coal companies. I mean…</rambling>
P.S. IMHO 1M context is just inviting more problems until the underlying models get stronger.